Research Intern
-
TencentJun 2026 - Present
I contribute to infrastructure for large-scale generative multimodal LLM post-training, build and maintain internal framework components for reinforcement-learning-based model training workflows, and support reliability and scalability improvements in production-oriented LLM training pipelines.
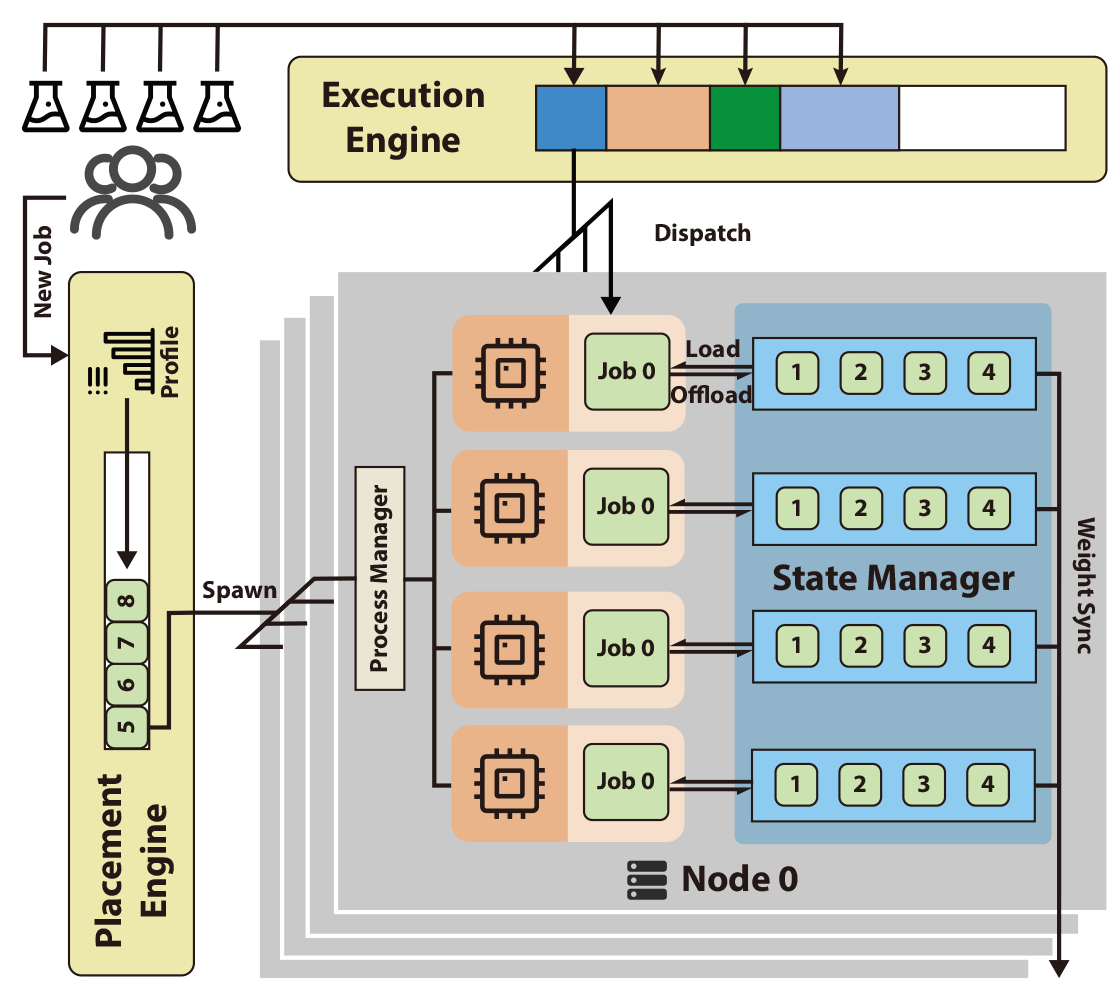
I worked on infrastructure for large-scale agentic post-training. My projects centered on cluster-level orchestration for RLVR, service-oriented RL training, and unified model-state management, including PlexRL, Weaver, and the NexRL/Nex-N1 ecosystem.
The core systems theme was to turn post-training into an AI infrastructure problem: scheduling heterogeneous jobs, recycling idle GPUs across workloads, decoupling rollout/training/tool services, and hiding low-level parallelism details from algorithm designers.
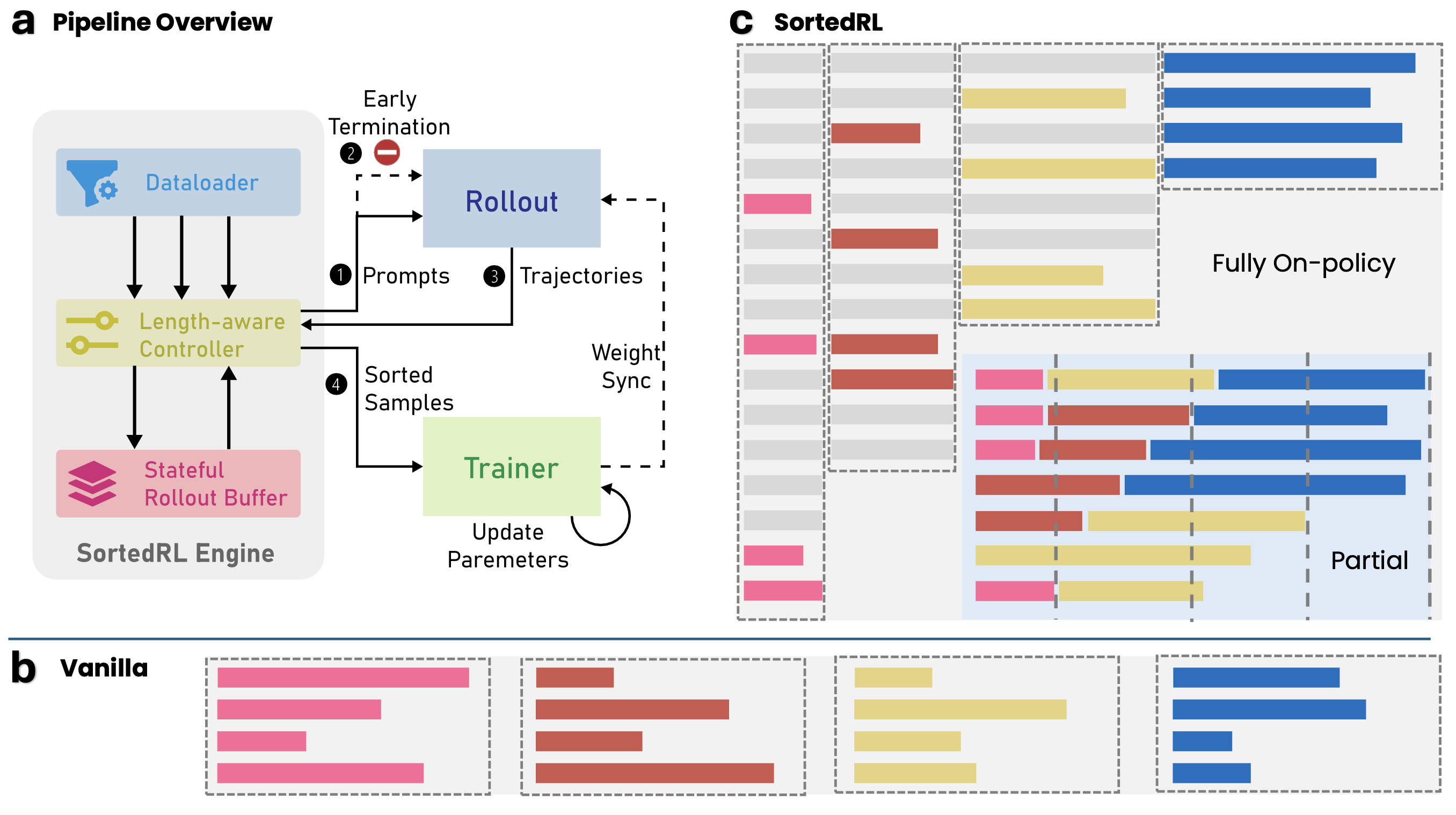
I developed SortedRL, a system for online length-aware rollout scheduling in LLM reinforcement learning. It exploits output-length distribution during training to reduce rollout bubbles, construct efficient update batches, and maintain policy freshness.
The resulting scheduler reduced rollout scheduling bubbles by about 70% and cut the number of training steps for reasoning-model workloads by about 50%.
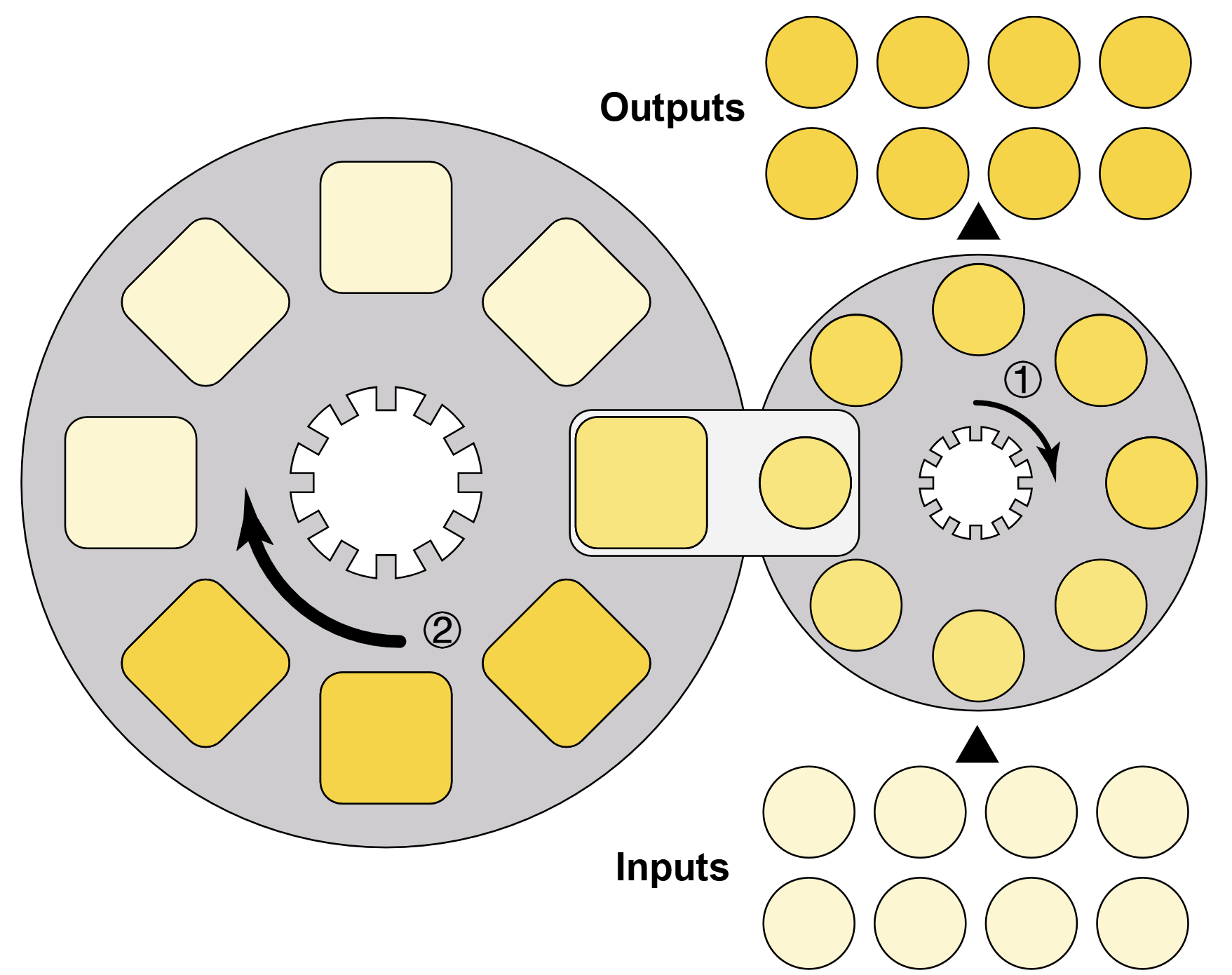
My PhD research focuses on systems for LLM training and inference under constrained accelerator memory. In the NeurIPS 2024 paper SpeedLoader, I redesigned data movement for offloaded and sharded LLM operation across heterogeneous hardware.
The broader goal is to make large-model infrastructure less bottlenecked by memory hierarchy, communication, and runtime scheduling overhead.
Graduate Researcher
-
KCL IoPPNApr 2022 - Jan 2023
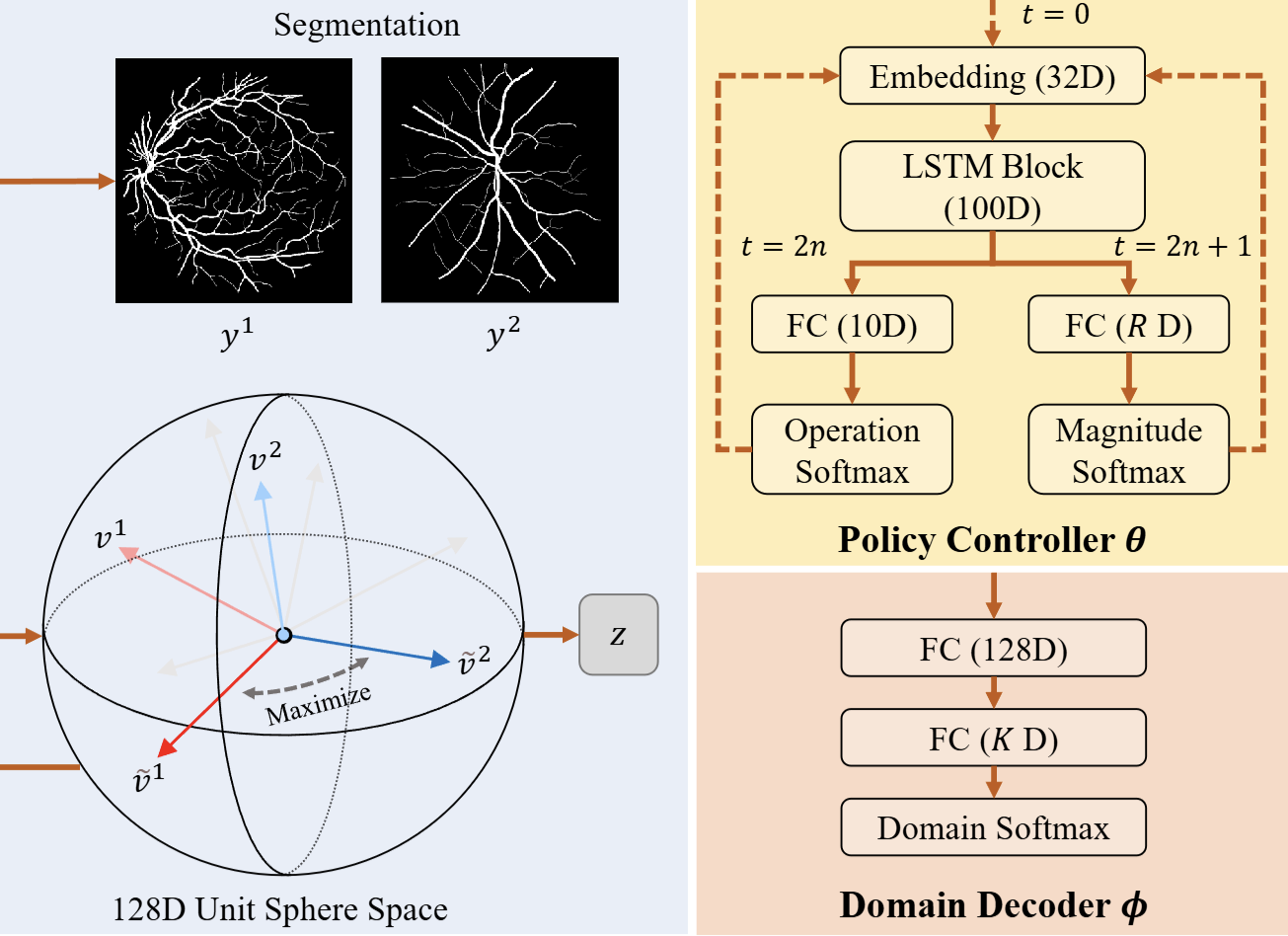
Earlier in my research path, I worked on neuroimaging systems and medical image reconstruction. At King’s College London’s Institute of Psychiatry, Psychology & Neuroscience, I designed an explainable super-resolution framework for ultra-low-field MRI and applied Bayesian model selection to choose reliable models at inference time.
I contributed to medical image augmentation for domain generalization, using statistical evidence to maximize data diversity and improve model generalizability. This work sits earlier in my ML trajectory, before my current focus on LLM systems and AI infrastructure.
This was my foundation in high-performance computing and performance engineering. I benchmarked new devices and software stacks, optimized scientific applications such as Relion, Presto, and DLRM, and ported the discrete unified gas kinetic scheme to heterogeneous platforms with up to 16x speedup.